
Postgres - ćwiczenia

Przypominam sobie SQL
Ćwiczenia SQL
W ramach treningu SQL-a i poznawania postgresa robię (powoli) ćwiczenia ze strony pgexercises.com.
Można na stronie rozwiązywać mini-zadania w różnych kategoriach (od prostych wyszukiwań przez złączenia, modyfikacje danych, aż po funkcje agregujące). Schemat bazy danych do ćwiczeń jest bardzo prosty, ale z niektórymi zadaniami miałam pod górkę:
Dlatego uważam, że stronka w sam raz nadaje się do odświeżenia wiadomości o SQL-u.

Swoje odpowiedzi z komentarzami wrzucę pewnie za jakiś czas do GitHuba jako gist.
Postęp !
Obecnie przechodzę przez “dział” z funkcjami agregującymi. Swój “postęp” widzę na stronie w postaci listy z “odhaczonymi” ćwiczeniami:
Moje dotychczasowe odkrycia:
- jeśli kolumna ma typ timestamp i potrzebuję wybrać wiersze dotyczące pewnej daty, to mogę:
- w warunku
WHEREużyć operatorów porównania z literałem napisowym oznaczającym datę, czyli np. poszukując eventów mających miejsce 10 maja 2017 roku mogę mapisaćevent < '2017-05-11' and event >= '2017-05-10' - lub użyć funkcji, która podaną wartość typu
timestamp“zaokrągli” do podanej “pozycji”, zerując “pozycje” o mniejszym znaczeniu:where date_trunc('day', event) = '2017-05-10'
- w warunku
- wstawiając wyliczone dane instrukcją
insertzamiastmuszę napisać1 2insert into cd.facilities(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance) values (select max(f.facid) + 1 as facid from cd.facilities f, 'Spa', 20, 30, 100000,800);i na razie nie rozumiem, dlaczego pierwsza składnia jest niepoprawna.1 2insert into cd.facilities (facid, name, membercost, guestcost, initialoutlay, monthlymaintenance) select (select max(facid) from cd.facilities)+1, 'Spa', 20, 30, 100000, 800;
Arytmetyka dat i funkcje związane z czasem
Postgres ma wiele ciekawych funkcji, których można użyć w zapytaniach, dzięki czemu nie trzeba już ich wyliczać w języku programowania. Na przykład:
- wykonując operacje na datach można użyć bardzo intuicyjnej arytmetyki
- dodatkowe funkcje pozwalają tworzyć wartości typów interwałowych, daty czy timestampów
Plany
Po zakończeniu ćwiczeń z SQL-a zamierzam przyjrzeć się bliżej interesującym mnie obszarom:
- typom
jsonijsonborazjsonpathpozwalającym na wyszukiwanie danych w obiektach json json types - typom związanym z geometrią pozwalającym przechowywać punkty, proste, wieokąty, koła czy ścieżki
- tablicom, a właściwie typom tablicowym
- zakresom range types
Oprócz tego postgres obsługuje wiele innych typów (adresy internetowe, identyfikatory obieków, typy domenowe, typy złożone), o których na razie wiem tylko tyle, że postgres je obsługuje 🤔.
Dokumentacja funkcji oferowanych przez postgresa naprawdę robi wrażenie; chciałabym je choćby pobieżnie przejrzeć; w szczególności chciałabym poznać funkcje agregujące i “okienkowe”, i spróbować ich użyć podczas praktycznej analizy prawdziwych danych.
Zobaczymy - drzemki mojej córeczki są coraz krótsze, czasu coraz mniej, a do odkrycia tyle interesujących rzeczy 😄.
Aktualizacja 2021-10-05
Nie można użyć aliasu kolumny w klauzuli HAVING
Postgres nie pozwala na użycie aliasu kolumny (np. wyliczonej złożoną formułą przy użyciu funkcji agregującej) w klauzuli having; trzeba
- powtórzyć wyliczenie w klauzuli
havingalbo - zapakować wywołanie w zewnętrzny
selecti użyć zwykłego warunkiwhere
Tego dowiedziałam się próbując optymalnie rozwiązać zadanie o przychodach. Natknęłam się na poniższy błąd:
|
|
Musiałam więc użyć drugiego sposobu, czyli:
|
|
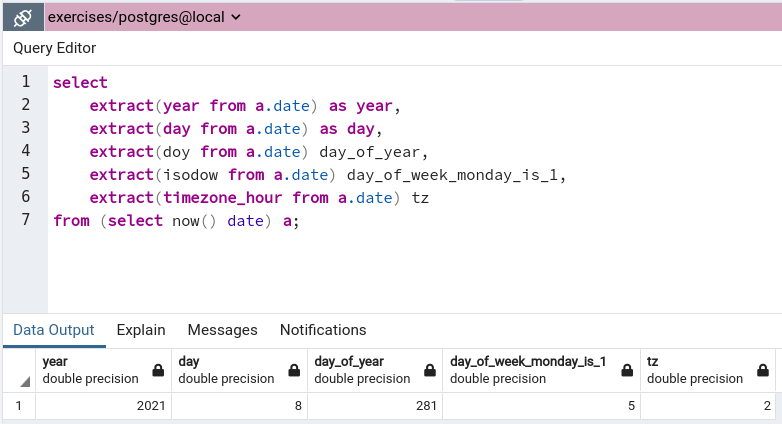
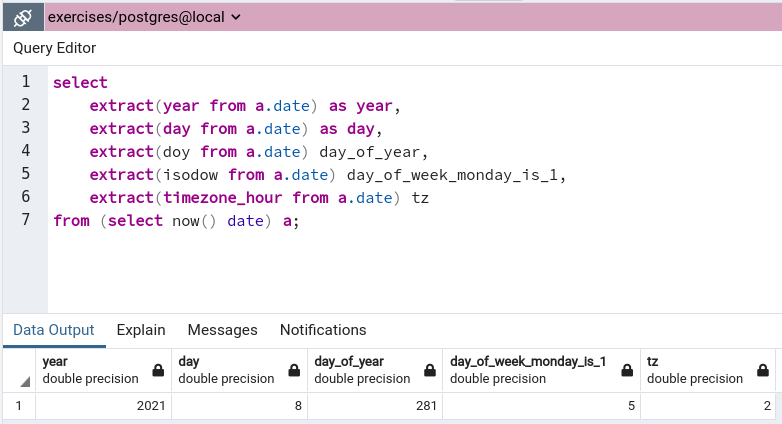
Funkcja extract
Składnia:
extract (field from source)
Jako source można podać wartość typu timestamp, date (będzie zrzutowany na timestamp), time oraz interval.
Wartość field to jedna wartość z: century, day, decade, dow, doy, epoch, hour, isodow, isoyear itd (pełna lista).
Można, zamiast date_part('month', eventstamp) użyć funkcji extract(month from eventstamp), chyba łatwiej się ją wprowadza, bo nie trzeba wpisywać apostrofów przy literale napisowym :)
Na przykład:
|
|
ROLLUP
O, to jest świetne: można łatwo policzyć sumy częściowe i zbiorcze hierarchicznie (przykładowe zadanie):
|
|
ROUND
Zaokrągla wartość do podanej liczby miejsc po przecinku. Użyłam w ten sposób, choć nie wiedziałam wcześniej, że taka funkcja istnieje. Może jest w standardzie i/lub używałam jej już wcześniej?
Ponieważ zaokrąglanie jest bardziej złożone, niż może się wydawać, sprawdzam w dokumentacji jak działa round:
Rounds to nearest integer. For numeric, ties are broken by rounding away from zero. For double precision, the tie-breaking behavior is platform dependent, but “round to nearest even” is the most common rule.
|
|
Windowing functions
Pierwsze możliwe użycie w zadaniu count members - tym razem przeczytałam rozwiązanie. A później:
- tutorial wprowadzający w temat funkcji okienkowych
- składnia funckji okienkowych
- funkcje okienkowe wymagają zastanowienia - mam dość mizerną intuicję na temat tego, w jakich sytuacjach się je stosuje
Correlated subqueries
Skorelowane podzapytanie pojawiło się w zadaniu rolling average.
Ciekawe: używamy zapytania z funkcją generate_series (jest to jedna z tzw. set generating functions) do wygenerowania listy dat z pewnego miesiąca. Później wykonujemy zapytanie dla każdej wygenerowanej w ten sposób daty (wygenerowany zbiór z datami znajduje się w sekcji FROM, a sam SELECT wybiera dwie kolumny: datę oraz średnią wyliczoną przy pomocy zapytania skorelowanego.
To jest przykładowe rozwiązanie rolling average:
|
|
Moje próby były niestety nieudane. To jedna z moich zawiłych prób liczenia średniej:
- niepoprawnie założyłam, że mam dane dla wszystkich dni sierpnia 2012 ORAZ dane dla wszystkich 15 dni poprzedzających 1 sierpnia
- próbowałam najpierw liczyć sumy przychodów grupując po dniach (all_revs)
- a później liczyłam średnią funkcją okienkową zawierającą 16 dni bez dnia bieżącego (żeby złapać 15 poprzednich)
- … przy czym trochę się męczyłam arytmetyką dat:
|
|
Wniosek: czas przerobić kolejny dział daty i przyjrzeć się funkcjom z nimi związanym.
Gist
Dokumentację moich rozwiązań zamieściłam w tym miejscu: gist.
Ten wpis jest częścią serii sql.
- 2021-04-11 - Postgres - daty
- 2021-16-10 - Postgres - krótka analiza danych dot. zajęć dodatkowych
- 2021-04-10 - Postgres - JSON
- 2021-04-10 - Postgres - ćwiczenia
- 2021-30-09 - Postgres - instalacja